1 | #include <filesystem> |
cplusplus里数据类型的大小和存储方式
不同数据类型的大小
相同位数的系统下,每一个变量的地址大小相同
1 | int32_t va; int32_t* vb; double vc; double* vd; uint8_t ve; uint8_t* vf; intptr_t vg; |
以上变量地址大小都是 8 ,因为在64位体统下。
相同位数的系统下,不同类型变量占有的空间大小不同
1 | int32_t va; int32_t* vb; double vc; double* vd; uint8_t ve; uint8_t* vf; intptr_t vg; |
这里*vb == vb[0]
不同位数的系统下,不同/相同变量占有的大小不同

当申请一块 uint_8* buff 时,系统划分出一个8字节的大小,存储了一个指向随机位置的指针。
buff = (uint_8*)calloc(seizeof(*buff) * 10,0 ); 时,buff指向了一块地址。这块地址保存的都是十个 1字节的uint_8数据。
1 | uint8_t* aa; |
uint8 int float double 怎么在计算机内存储
uint8:占一个字节八位, 无符号数,0~255,算数or逻辑左移右移就是左右移动,舍去移动的位数然后补零
int32 :四个字节32位,有符号数,最高位代表符号。
最大数2147483647的原码为0111 1111 1111 1111 1111 1111 1111 1111
最小数-2147483648的补码表示为1000 0000 0000 0000 0000 0000 0000 0000,在32位没有原码。
对有符号数逻辑左右移动不考虑符号,算数右移补符号位。
float32: 四字节32位,有符号数,最高位代表符号。E代表指数 2E M代表尾数

Shell指令
语法基础
写入bashrc中,通过vim ~/.bashrc 编辑本机各种快捷键
作为可执行程序
将代码保存为name.sh,并 cd 到相应目录
chmod +x ./test.sh #使脚本具有执行权限
./test.h 运行,或者将文件拖入终端运行
注意,一定要写成 ./test.sh,而不是 test.sh,运行其它二进制的程序也一样,直接写 test.sh,linux 系统会去 PATH 里寻找有没有叫 test.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 test.sh 是会找不到命令的,要用 ./test.sh 告诉系统说,就在当前目录找。
#! 是一个约定的标记,它告诉系统这个脚本需要什么解释器(sh、bash、php等等)来执行。
使用模版
1 | #!/bin/bash |
https://www.runoob.com/linux/linux-command-manual.html
磁盘容量
磁盘容量: df -h
当前文件夹下,每个文件夹的大小 du -sh */
文件传输
从服务器传递到本机:
scp -r zoom@10.10.16.163:~/share5/users/yuanqi/datasets/FEED/ID_1 ~/Downloads
从本机传递到服务器:
scp -r /Users/PeppaZhu/Downloads/Actor_01 peppa@10.100.112.41:/data/peppa
文件链接
文件操作
1 | 删除文件 |
linux - Argument list too long error for rm, cp, mv commands - Stack Overflow
1 | 查看当前路径下文件个数(不包括下一级子目录里文件个数) |
Bilateral and Guided Filter
双边滤波 for gray and color images
原理
在滤波加权的时候计算几何相似度和光学相似度,在亮度差别大的地方不进行平均加权,从而达到保边。

公式

在上述公式中,k代表正则化,c(.)代表几何相似度,也就是距离, s(.) 代表光学相似度,可以是色彩的差,亮度的差等。
实验现象

如果只做色彩滤镜相当于对直方图进行压缩,也就是只做色彩滤镜相当于把全图色彩平均,向中灰度压缩。
当像素相似度比较大的时候(100~300),对于小的范围参数影响不大了,因为几乎小范围内的所有数据都在像素相似度内。整图结果主要由范围半径控制。
当范围半径比较大的时候,双边滤波更像是色彩相似度滤镜,表现为对直方图的压缩,现象就是偏灰。
常说到的导致梯度反转
首先,是双边滤波在做Tone Mapping时才会导致梯度反转。并不是直接用双边滤波得到保边平滑图就会出现梯度反转。
双边滤波在做Tone Mapping时,Fast Bilateral Filtering for the Display of High-Dynamic-Range Images ,将图像分成base层和ditail 层 base = BF(ori_img) detail = ori_img./base。由于base层在边缘处加权的数据少,所以不稳定,偏向没有边缘的那一侧的值。导致的detail层也不稳定,在增强或者压缩base后,叠加detail会出现梯度反转。

Guided Filter
目的
保边平滑,线性时间复杂度(与滤波半径无关),以及和matting Laplacian matrix理论有相似形式。可以用于:去噪,细节增强/平滑,HDR压缩,抠图,羽化,去雾,联合双边上采样。
原理

在一个小的局部区域,输出是guidance I 的一个线性变化,通过这个假设来确保,在局部,输出q的梯度和guidance I的梯度成比例,从而引入,或者说保留guidance I的梯度。
在一个局部的区域内,输出q,或者说是去噪音后的输入p,是引导图I的一个kI+b的线性变化。kI也就是,引导图的变化趋势都被保留,b是为了模拟p所在域的bias。eps控制a不能太大,这项是为了控制平滑(模糊)程度的
公式



公式意义:
当I没有梯度的时候,a等于0 ;当p没有梯度的时候,a等于0; 也就是任意一方是平坦图的时候,输出q 退化为p的两次boxfilter
当I有比较大的梯度,p也有比较大梯度,且他们有相关性的时候(分母一定,也就是I方差一定,Ip相关性越大分子越大),a越大,I的梯度得到保留;
当引导图的方差远小于eps时,a几乎等于0,像素被平滑,也就是引导图方差相对于eps的关系决定了平滑的力度。
对于引导图I,滤波图p为一副图的情况,a = 方差/方差+eps b = avg - a*avg。输出就变成了根据方差和eps关系,来选择性输出原图或者是avg图。对于方差比较大的边缘,输出原图的权重高,对于方差比较小的地方,输出平均图的权重高。
公式几何意义:在一个局部区域内,I为横轴p为纵轴,q = aI+b,也就是一条直线尽量拟合每一个(I,p) ,那么根据这个拟合结果,可以对原本的p有一个新的输出q。

考虑到eps 对a的限制,输出可能更平滑一些

线性复杂度:由于一个固定方框内的均值方差可以采用box filter的优化方式变成线性复杂度,因此本算法也可以优化成线性复杂度。
实验现象
参数: GuidedFilter(guided,10,0.000001),对于引导图是黑白图像,输出会引入边缘处其他梯度,会导致有些边缘模糊。模糊可能是因为,第一,p在该区域不全为0,有梯度变化。引导图在该区域有梯度,a有值,再加上a的平均,导致在边缘区域加入了引导图。第二,引入边缘处的梯度就是不完全的加权加了一部分原图的自然结果。且a并不是1,是-1~11的数据。简单来说,在边缘处黑度图他们不可清晰分类。




对于引导图是彩色图,其结果好转。彩色图在计算时,a是引导图三通道3*3方差 * (I * P), 也就是单独通道颜色不匹配(哪怕亮度匹配),a依旧很小。防止引入相同亮度不同颜色的边缘信息。简单来说,在rgb色彩空间,边缘可分。
抠图潜在危险
半径不能太大。不然线性无法拟合。而且脸部要是有白色高光容易和背景墙混淆。
几乎完全相同颜色的边缘信息会引入。比如白色衣服白色墙体。黑色头发黑色椅子,因为本质上相同颜色不可分。于是会出现更多错误。
边缘处有rgb色彩重叠,会有些错分,带来就是部分引入错误,淡化原本01的强分割边界。
代码
https://github.com/lisabug/guided-filter
针对于抠图的潜在危险设计的S_Guided Filter
针对于缺点2,设计了选择区域的GF,总的来说是颜色差别较大的区域Guided Filter生效,当颜色差别较小的区域不使用Guided Filter
具体做法:在算引导图I 方差的时候,标记I 大于一定值的区域作为生效区域。当引导图为彩色图是,存在IR,IG,IB三个和mask相关的协方差,选取最大那个作为判定值。(因为当有一种颜色R G B,可和I相关,用以区分时,这个区域就可以区分)。
引入的危险:阈值如何计算。太小了的话,那些高噪音的平台区域也变成working area了,太大了的话,一些本来可以使用GF的区域也失效了。
测试case:尽量让浅肤色和白墙,深色头发和黑墙可以区分,不让白衣服白墙,全黑衣服和黑墙,以及高噪音全黑衣服和黑墙引入错误。
针对于缺点3,对GF后的结果进行了一些拉伸,让分割锐利,且剔除被分到前景的背景,但不在原基础上新增内容(可能有的前景被CNN分到了背景但是GF也无法加回来了)
具体做法:
•Q, Workingarea = GuidedFilter(guidedI,ori_mask) ;//得到可分区域或者纹理复杂区域
•Q是GF算法的直接结果,包含错分区域,纹理复杂区域,以及正确区域
•M = ori_mask - Q;//改变值, M本身在-1~1之间
•M = M * 2 – 0.3(beta);//将改变的数据进行拉伸,后在-2.3 ~1.7之间放大改变值的。
•M[M<0]= 0; // 1:不会新添加东西 2:如果改变值过小就忽视 。
•M[M>1] = 1; //数据合理性约束
•Output = (Workingarea == TRUE)? (ori_mask – M) : ori_mask
•Output < 0 = 0; // 数据合理性
引入的危险:*2 - 0.3 是手调拉伸超参数。为了保证变化锐利而非自然。且舍弃了将前景补足的潜力。
测试case:卷曲的头发剔除背景合理,不增加黑头发后面的复杂背景。
卡尔曼滤波
卡尔曼滤波
更通用的,一个变量(状态)的卡尔曼滤波
就是利用历史数据(根据状态转移方法)预测新数据,并且根据当前观测的新数据值,和其不确定性,综合修正预测的数据。
干了这么
如果有两个系统对一个数据(高度,位置或者其他的)都有测量或者说是观测,但是都不准。那如何通过这两个不准的东西得到一个更准的结果。
更简单的说法:怎么去求两个数据的加权平均
如何通俗并尽可能详细地解释卡尔曼滤波? - Kent Zeng的回答 - 知乎 https://www.zhihu.com/question/23971601/answer/26254459
翻译理解
接下来按照
https://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/
一文简单翻译理解一下 这是一个多变量 运动定位系统
what is it ?
你有一个不准确但是可以观测的,连续变化的系统。此外,你还能对着干观测值进行一些科学的推论。但是也不准。通过卡尔曼滤波(合理的对不准确的推理和不准确的观测结果加权),可以得到一个更准确的当前值的结果。
what can we do with a Kalman filter
假设你有一个小机器人,这个机器人在森林里行走,需要定位。
这个小机器人有一个状态,这个状态包括了当前位置和当前速度。这个速度是某种码表里可以读出来的。此外,这个机器人还有一个GPS定位,表明了当前的位置。不管是GPS还是速度都是不太准的的。怎么得到更准确的当前位置呢?
how a Kalman filter sees your problem
我们有两个连续变化的数据(假设都服从高斯分布),位置和速度,虽然这些都不准,方差衡量了不同变量各自的不确定性,协方差衡量了他们之间的关系。
Describe the problem with martics
我们可以得到,当前状态的(速度和位置)的均值,然后和这两个变量之间的斜方差矩阵
下一步,我们可以通过p = p + vt 得到下一次的位置,速度预测。这步就是科学推倒得到的合理的预测。同时更新均值和其斜方差。
此外,考虑再复杂一些,我们加入外力(加速度)和不确定性。
最终影响下一次状态的均值的是,当前状态以及外力,影响下一次斜方差的是当前斜方差,不确定噪音。
Refining the estimate with measures
我们可以通过直接读数,得到一个位置速度分布的概率。我们还可以通过科学推倒得到一个速度位置分布的概率。那将这两个概率相乘归一化,就是更准的概率了。
putting it all together
新的位置等于 根据老位置预测出来的新位置,以及新位置读数的加权。加权值由推倒公式,读数概率等原始数据共同决定。
git在干什么
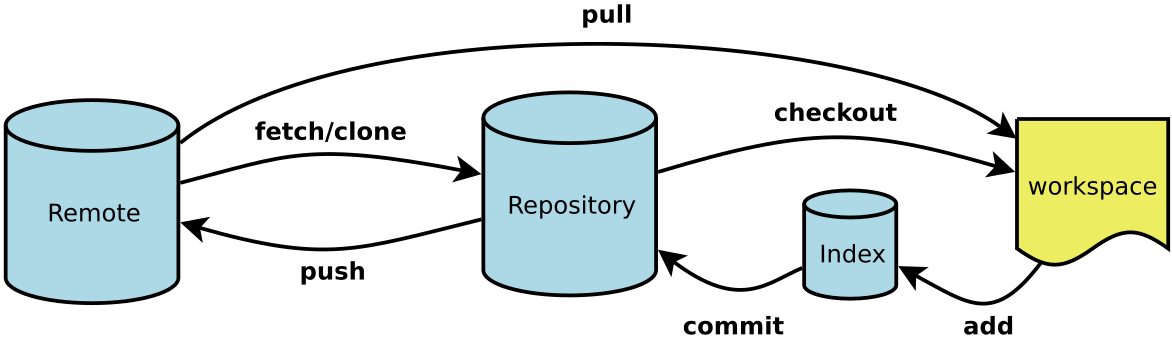
git pull
1.0 如果在本地有更新,但是没有commit, pull会失败 ?不会,如果本地有更新,但是远程没有更新,pull好像没啥区别。
1.1 但是不是远程有更新,本地也有更新,并且本地没有commit这时候pull才会失败?
1.2 正常来说,需要commit将本地更新记录到本地仓库 或者 checkout . 把本地跟新的退回
2 假设本地我修改了A文件,别人在远方修改了B文件,我commit后pull,B文件会被更新,但是A文件我的修改不会丢失
3 假设本地我修改了A文件,别人在远方修改了A文件,我commit后pull会失败,需要git pull origin sara-ep-attlit –rebase
参考
https://www.jianshu.com/p/27718f0741d8
https://www.jiqizhixin.com/articles/2020-05-20-3
http://chuquan.me/2022/05/21/understand-principle-of-git/
https://xiaowenxia.github.io/git-inside/2020/12/06/git-internal.objects/index.html
git 指令
Git 指令
1 | 列出所有本地分支 |
https://www.cnblogs.com/ellen-mylife/p/12794245.html
https://www.ruanyifeng.com/blog/2015/12/git-cheat-sheet.html
https://blog.csdn.net/dingyi4815313/article/details/114068189
Fatal: Not possible to fast-forward, aborting - 简书](https://www.jianshu.com/p/5f4772dc60c2)
1 | 场景1 无干扰提交文件 |
git–本地分支与远程分支_Andyato0520的博客-CSDN博客
1 | 拉代码 |
1 | merge 分支,将主分支 dev-video merge到自己的分支dev-video-attlit上: |
1 | 从当前分支master 拉出新分支 dev |
git从已有分支拉新分支开发_git 拉取新分支_苦咖啡-bit的博客-CSDN博客
https://www.runoob.com/git/git-branch.html
git 拉取远程指定分支 pull本地不存在的分支 - 哈姆PP - 博客园
1 | 反正就是解决不了冲突或者不在分支上 |
1 | 删除git分支 |
1 | 关于tag |
Git: git tag 使用小结(给发布版本打标记,切换并修改某个历史版本) - 夜行过客 - 博客园
Git配合GPG签名
1 | 当配置好GPG之后 每次commit |

https://git-scm.com/book/zh/v2/Git-%E5%B7%A5%E5%85%B7-%E9%87%8D%E5%86%99%E5%8E%86%E5%8F%B2
git 配合beyond compare
mac 安装位置如下
1 | git config --global mergetool.bc4.cmd '"/Applications/Beyond Compare.app/Contents/MacOS/bcomp" "$LOCAL" "$REMOTE"' |
c++程序编译过程
c++ 程序编译过程
总的来说分成四个阶段:预处理 编译 汇编 链接
预处理
- 预处理器(cpp)将所有的#define删除,并且展开所有的宏定义(例如#define PI 3.14 这句在预处理阶段,后期的所有PI都会被替换成3.14)。
- 处理所有的条件预编译指令,比如#if、#ifdef、#elif、#else、#endif等。
- 处理#include预编译指令,将被包含的文件直接插入到预编译指令的位置。
- 删除所有的注释。
- 添加行号和文件标识,以便编译时产生调试用的行号及编译错误警告行号。
- 保留所有的#pragma编译器指令,因为编译器需要使用它们。
- 使用
gcc -E hello.c -o hello.i命令来进行预处理, 预处理得到的另一个程序通常是以.i作为文件扩展名。
读取源代码并对其中的以#开头的指令和特殊符号进行处理。包括宏定义,条件编译,头文件,特殊符号。将.cpp 转化成 .i
编译优化
首先 通过词法分析和语法分析,确认所有的指令都符合语法规则。其次将其翻译成等价的中间代码表示或汇编代码。template和inline函数在此阶段处理。优化一部分是对中间代码的优化。这种优化不依赖于具体的计算机。另一种优化则主要针对目标代码的生成而进行的,和硬件有关。将 .i 转化成.s
全局变量,静态全局变量,类的静态数据成员,都在编译时分配内存空间,完成初始化。
而静态局部变量则是在第一次使用到的时候分配内存并且初始化。
汇编
将汇编代码转换成二进制机器码
通常一个目标文件中至少有两个段,代码段和数据段. 将 .s 转化成.o
链接
链接程序的主要工作就是将有关的目标文件彼此相连接,使得所有的这些目标文件成为一个能够被操作系统装入执行的统一整体。主要分动态链接(.so)和静态链接(.a) .将 .o 转化成.out
| 后缀名 | 描述 |
|---|---|
| .c/.C/.cc/.cp/.cpp/.cxx/.c++ | 源代码文件,函数和变量的定义/实现 |
| .h | 头文件,函数和变量的声明 |
| .ii | 编译预处理产生的文件 |
| .s | 编译产生的汇编语言文件 |
| .o (.obj in Windows) | 编译产生的中间目标文件 |
| .a | 打包目标文件的库文件 |
| .so | 编译产生的动态库文件 |
| .out (.exe in Windows) | 链接目标文件产生的可执行文件 |
VC++6.0中Compile和Build的区别
“compile”是“编译”的意思,“build”是“链接”的意思。
compile 的作用是对你的代码进行语法检查,将你的文本程序语言转化成计算机可以运行的“01010….”形式的二进制文件。
build 的作用是将你在程序中调用到的类库融合到你的程序中,比如你用到了printf()函数,那么内部实现该函数的类库代码就会添加到你的程序中。
compile过程生成“.obj”文件或”.o”文件,这个和编译器有关,vc++中是“.obj”文件。
build过程生成“.exe”文件。这个可以直接运行
理论上来说应该先点”complile”,再点”build”。不过在vc++中直接点“build”它会自动先给你compile再build
参考
https://blog.csdn.net/u011718663/article/details/118163962
https://blog.csdn.net/hexkang/article/details/126402730
mac 连接网盘
Mac 连接到服务器并在代码中访问
在go中选择 connect to severe
输入服务器地址 例如ftp://10.100.116.21 smb://
选择connect按钮
根据输入的连接类型和地址 输入相应的账户密码即可连接
ftp与smb的不同
Smb 可以提供用户登入 SAMBA 主机时的身份认证,以提供不同身份者的个别数据, 所以输入的账户密码可能克ftp不同,且访问到的文件夹和ftp也不同
访问时
/Users/../../Volumes/10.100.116.21/
或者直接相对路径一路../../
找不到时
在 Finder 里Finder Setting 里 show Connected servers 勾选上